Mathematical Background |
This web page is a revised and extended version of Appendix A from the book Conceptual Structures by John F. Sowa. It presents a brief summary of the following topics for students and general readers of that book and related books such as Knowledge Representation and books on logic, linguistics, and computer science.
Curly braces are used to enclose a set specification. For small, finite sets, the specification of a set can be an exhaustive list of all its elements:
{1, 97, 63, 12}.
This specifies a set consisting of the four integers 1, 97, 63, and 12.
Since the order of listing the elements is immaterial, the following specification
is equivalent to the one above:
{12, 63, 97, 1}.
If the set is very large, like the set of all mammals, a complete listing
is impossible. It is hard enough to enumerate all the people in a single
city, let alone all the cats, dogs, mice, deer, sheep, and kangaroos in
the entire world. For such sets, the specification must state some rule
or property that determines which elements are in the set:
{x | vertebrate(x) and warmBlooded(x) and hasHair(x) and lactiferous(x)}
This specification may be read the set of all x such that x is vertebrate,
x is warm blooded, x has hair, and x is lactiferous. A given set may
be specified in more than one way. The following four specifications all
determine the same set:
{1, 2, 3}
{x | x is an integer and 0<x<4}
{x | x is a positive integer, x divides 6, and xą6}
{x | x=1 or x=2 or x=3}
A set specification that lists all elements explicitly
is called a definition by extension. A specification that states
a property that must be true of each element is called a definition by
intension. Only finite sets can be defined by extension. Infinite
sets must always be defined by intension or by some operations upon other
infinite sets that were previously defined by intension.
In any theory using sets, there are two privileged sets: the empty set {}, which contains no elements at all, and the universal set U, which contains every element that is being considered. In mathematical discussions, for example, the universal set may be the set of all integers Z or the set of all real numbers R. In most discussions, the universal set is usually defined at the beginning of the presentation. Thereafter, other sets are built up from U: subsets of U, pairs of elements of U, sets of sets of elements from U, etc.
Of all the operators that deal with sets, the most basic is Î, which states whether a particular element is in a set: the notation xÎS means that x is an element of the set S; it may also be read x is a member of the set S or simply x is in S. All other operators on sets can be defined in terms of Î. Let A and B be any two sets. Following are the common operators of set theory; listed for each one is its name, standard symbol, informal English definition, and formal definition in terms of Î:
AČB = {x | xÎA or xÎB}.
AÇB = {x | xÎA and xÎB}.
-A = {x | xÎU and not xÎA}.
A-B = {x | xÎA and not xÎB}.
If xÎA, then xÎB.In particular, every set is a subset of itself: AĚA.
If xÎA, then xÎB and there exists some b where bÎB and not bÎA.
For complex sets, the rule for determining which elements are in the set may be too complex to state in a single expression. An example is the set of all grammatical sentences in some language, natural or artificial. Such sets are typically specified by a recursive definition:
S = {x | x is an integer, x>0, and 3 does not divide x}.
But the property x is an integer depends on some prior definition
of the set of all integers. The following recursive definition depends
only on the operation of adding 3:
A set has no duplicate elements. Since all duplicates are discarded in computing the union of two sets, the union operator is idempotent: AČA=A. In some cases, one may want to allow duplicates; therefore, a bag is a collection of things with possible duplicates. Since there may be more than one occurrence of a given element x, the count operator @ is a generalization of the element operator Î. The expression x@A is the number of times the element x occurs in the bag A. Bags are useful for many purposes, such as taking averages: if four men have heights of 178cm, 184cm, 178cm, and 181cm, then the set of those numbers is {178, 181, 184} with the average 181; but the bag of the numbers is {178, 178, 181, 184} with average 180.25.
A sequence is an ordered bag. To distinguish ordered sequences from unordered sets and bags, the elements of a sequence are enclosed in angle brackets: á178, 184, 178, 181ń; the empty sequence is written áń. If a sequence has n elements, the elements are numbered from 1 to n (or alternatively from 0 to n-1). A sequence of two elements is sometimes called an ordered pair; a sequence of three elements, a triple; a sequence of four, a quadruple; a sequence of five, a quintuple; and a sequence of n elements, an n-tuple. Historically, the theory of sets was first defined without considering order. On a piece of paper or in computer storage, however, the elements of a set must be listed in some order. Sequences are therefore easier to represent than bags, and bags are easier to represent than sets: a bag is a sequence with the ordering ignored, and a set is a sequence with both order and duplicates ignored.
New sets may be created by combining elements from the universe U in various ways. The cross product of two sets A and B, written A?B, is the set of all possible ordered pairs with the first element of each pair taken from A and the second element from B. If A is the set {1,2} and B is the set {x,y,z}, then A?B is the set,
{á1,xń, á1,yń, á1,zń, á2,xń, á2,yń, á2,zń}.
With the notation for defining a set by a property or rule, it is possible
to give a general definition for the cross product
A?B:
{áx,yń | xÎA and yÎB}.
The cross product can also be extended to three or more sets. The product
A?B?C is defined as
{áx,y,zń | xÎA, yÎB, and zÎC}.
Since Ren? Descartes introduced pairs of numbers for identifying points
on a plane, the cross product is also called the Cartesian product
in his honor.
In this book, most sets are finite. Inside a computer or the human brain, all sets that are explicitly stored must be finite. But mathematical definitions and proofs are generally simpler if there is no upper limit on the size of sets. Therefore, definitions in computer science often permit infinite sets, but with the understanding that any implementation will only choose a finite subset. Most infinite sets discussed in computer science are assumed to be countable: a countably infinite set is one whose elements can be put in a one-to-one correspondence with the integers. The set of all real numbers is uncountable, but such sets are far beyond anything that can be implemented in computer systems.
The terminology for sets is quite standard, although some authors use the word class for set and others make a distinction between classes and sets. Bags are not used as commonly as sets, and the terminology is less standard. Some authors use the word multiset for a bag. Sequences are sometimes called lists or vectors, but some authors draw distinctions between them. Some authors use the symbol Ć for the empty set, but the notation {} is more consistent with the notation áń for the empty sequence.
Suppose Z is the set of all integers, and N is the set of non-negative integers (i.e. the positive integers and zero). Then define a function square: Z ® N with the mapping rule,
square(x) = x2.The function square applies to all elements in its domain Z, but not all elements in its range N are images of some element of Z. For example, 17 is not the square of any integer. Conversely, some elements in N are images of two different elements of Z, since square(3)=9 and square(-3)=9.
A function is onto if every element of its range is the image of some element of its domain. As an example, define the absolute value function, abs: Z ® N, with the mapping,
+x if xł0 abs(x) = -x if x<0Every element of N is the image of at least one element of Z under the mapping abs; therefore abs is onto. Note that abs is onto only because its range is limited to N. If the range had been Z, it would not be onto because no negative integer is the absolute value of anything in Z.
A function is one-to-one if no two elements of its domain are mapped into the same element of its range. The function abs is not one-to-one because all the elements of N except 0 are the images of two different elements of Z. For example, abs(-3) and abs(3) are both 3. As a more subtle example, consider the function g: Z ® N with the mapping,
g(x) = 2x2 + x.Then g(0)=0, g(1)=3, g(-1)=1, g(2)=10, g(-2)=6, etc. The function g is one-to-one since no two elements of Z are mapped into the same element of N. However, g is not onto because many elements of N are not images of any element of Z. Note that g is one-to-one only over the domain Z of integers. If its domain and range were extended to the set R of all real numbers, it would not be one-to-one: g(-0.5) and g(0), for example, are both 0.
A function that is both one-to-one and onto is called an isomorphism. The two sets that form the domain and range of the function are said to be isomorphic to each other. Let E be the set of even integers, and let O be the set of odd integers. Then define the function increment: E ® O with the mapping,
increment(x) = x + 1.This function is an isomorphism from the set E to the set O because it is both one-to-one and onto. Therefore, the sets E and O are isomorphic. Instead of the terms one-to-one, onto, and isomorphic, many authors use the equivalent terms injective, surjective, and bijective.
For many applications, isomorphic structures are considered equivalent. In old-fashioned computer systems, for example, holes on a punched card could represent the same data as magnetized spots on tape or currents flowing in transistors. Differences in the hardware are critical for the engineer, but irrelevant to the programmer. When programmers copied data from cards to tape, they would blithely talk about "loading cards to tape" as if the actual paper were moved. One mythical programmer even wrote a suggestion for reducing the shipping costs in recycling old cards: load the cards to tape and punch them out at the recycling works.
If f is an isomorphism from A to B, then there exists an inverse function, f -1: B ® A. The inverse of the function increment is the function decrement: O ® E with the mapping,
decrement(x) = x - 1.The composition of two functions is the application of one function to the result of the other. Suppose that f: A ® B and g: B ® C are two functions. Then their composition g(f(x)) is a function from A to C. The composition of a function with its inverse produces the identity function, which maps any element to itself. For any x in E, decrement(increment(x)) is the original element x.
Functions may have more than one argument. A function of two arguments whose first argument comes from a set A, second argument from a set B, and result from a set C is specified f: A?B ® C. A function with one argument is called monadic, with two arguments dyadic, with three arguments triadic, and with n arguments n-adic. Those terms are derived from Greek. Some authors prefer the Latin terms unary, binary, ternary, and n-ary. The number of arguments of a function is sometimes called its valence, adicity, or arity.
The rule that defines a function f:A®B as a mapping from a set A to a set B is called the intension of the function f. The extension of f is the set of ordered pairs determined by such a rule:
{áa1,b1ń, áa2,b2ń, áa3,b3ń,...}.
where the first element of each pair is an element x in A,
and the second is the image f(x) in the set B. A definition
by extension is only possible when the domain A is finite. In all
other cases, the function must be defined by intension. (One could, of
course, define the extension of a function as an infinite set, but the
set itself would have to be defined by intension.)
Since a function is a rule for mapping one set to another, the term mapping is sometimes used as a synonym for function. Another synonym for function is the term operator. Addition, subtraction, multiplication, and division are dyadic functions defined over the real numbers, but they are usually called operators. A common distinction is that functions have ordinary alphabetic names, but operators are designated by special symbols like + or ?. Traditional mathematical practice has tended to use several different terms as informal synonyms for functions:
It is possible, however, to allow two functions to be different on the ground that the rule of correspondence is different in meaning in the two cases although always yielding the same result when applied to any particular argument. When this is done, we shall say that we are dealing with functions in intension. The notion of difference in meaning between two rules of correspondence is a vague one, but in terms of some system of notation, it can be made exact in various ways.Church's way of making the notion precise was to define lamda calculus as a notation for defining functions and a method for converting any given definition into other equivalent definitions.
In mathematics, the traditional way of defining a function is to specify the name of a function and its formal parameter on the left side of an equation and to put the defining expression on the right:
f(x) = 2x2 + 3x - 2.This method of definition makes it impossible to specify the name f of the function independently of the name x of the formal parameter. To separate them, Church adopted the Greek letter l as a marker of the defining lambda expression:
f = lx(2x2 + 3x - 2).In this equation, the name f appears by itself on the left, and its definition is a separate expression on the right. The symbol x that appears after l is called the formal parameter or bound variable, and the remainder of the expression is called the body.
Church's rules for lambda conversion are formal statements of the common techniques for defining and evaluating functions. Whenever a function is applied to its arguments, such as f(5), the function may be evaluated by replacing the name f with the body of the definition and substituting the argument 5 for every occurrence of the formal parameter x. Church also defined additional operators, which combined with function evaluation to produce a computational system that is as general as a Turing machine.
With such rules, Church answered the question about equality of functions: they are equal by extension if they have the same sets of ordered pairs, and they are equal by intension if their definitions are reducible to the same canonical form by the rules of lambda conversion. An important result of the lambda calculus is the Church-Rosser theorem: when an expression has more than one function application that can be evaluated, the order of evaluation is irrelevant because the same canonical form would be obtained with any sequence of evaluations.
In computer science, the clear separation of the name of a function from its defining expression enables a lambda expression to be used anywhere that a function name could be used. This feature is especially useful for applications that create new functions dynamically and pass them as arguments to other functions that evaluate them. John McCarthy (1960) adopted the lambda notation as the basis for defining and evaluating functions in the LISP programming language. A common technique of computational linguistics is to translate natural language phrases to lambda expressions that define their semantics. William Woods (1968) used that technique for defining the semantics of the English quantifiers every and some as well as extended quantifiers such as more than two or less than seven. He implemented his definitions in LISP programs that translated English questions to lambda expressions, which were later evaluated to compute the answers. Richard Montague (1970) adopted a similar technique for his treatment of quantifiers in natural language semantics.
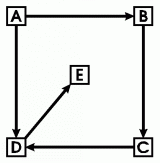
Figure 1: A sample graph
Formally, a graph G consists of a set N of nodes and a set A of arcs. Every arc in A is a pair of nodes from the set N. For the sample graph in Figure 1, the set of nodes is {A, B, C, D, E}, and the set of arcs is {áA,Bń, áA,Dń, áB,Cń, áC,Dń, áD,Eń}. Notice that node D happens to be an endpoint of three different arcs. That property can be seen instantly from the diagram, but it takes careful checking to verify it from the set of pairs. For people, diagrams are the most convenient way of thinking about graphs. For mathematical theories, a set of pairs is easier to axiomatize. And for computer implementations, many different data structures are used, such as blocks of storage for the nodes and pointers for the arcs.
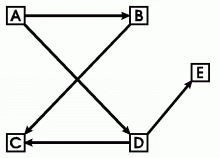
Figure 2: An alternate way of drawing the same graph as Figure 1.
Figure 2 is another way of drawing the same graph shown in Figure 1. The two diagrams look very different, but their abstract representations as sets of nodes and arcs are the same. Even when graphs are defined in a purely abstract way, questions may arise about the order of the two nodes of an arc. If the order is irrelevant, the notation {A,B} shows that the arc is an unordered set of two nodes. A graph whose arcs are unordered pairs is said to be undirected. If the order is significant, áA,Bń and áB,Ań represent distinct arcs, and the graph is said to be directed. For the directed graph represented in Figures 1 and 2, an arrowhead on each arc points to the second node of each ordered pair.
Although graphs are defined abstractly, mathematicians normally visualize them as diagrams. The common conventions for drawing graphs are reflected in descriptive terms like endpoint, loop, path, and cycle. Let e be the arc áa,bń. Then the nodes a and b are called endpoints of e, and e is said to connect a and b. If e is an arc of a directed graph, then the first endpoint a is called the source of e, and the second endpoint b is called the target of e. The word target is easy to remember since that is the direction the arrow points. A loop is an arc e whose endpoints are the same node: e=áa,ań.
Combinations of arcs are often named by the methods of traversing a graph. A walk through a graph is a sequence of nodes áa0, a1, ..., anń for which any two adjacent nodes ai and ai+1 are the endpoints of some arc. Any arc whose endpoints are adjacent nodes of a walk is said to be traversed by the walk. A walk that contains n+1 nodes must traverse n arcs and is therefore said to be of length n. A path is a walk in which all nodes are distinct. A walk with only one node áa0ń is a path of length 0. If the first and last nodes of a walk are the same, but all other nodes are distinct, then the walk is called a cycle. Every loop is a cycle of length 1, but cycles may traverse more than one arc.
For the graph in Figure 2, the walk áE, D, A, Bń is a path because all nodes are distinct. The path is of length 3, which is equal to the number of arcs traversed by a point that moves along the path. The walk áD, C, B, A, Dń is a cycle because it starts and ends at the same node.
If G is a directed graph, then a walk, path, or cycle through G may or may not follow the same direction as the arrows. A walk, path, or cycle through G is said to be directed if adjacent nodes occur in the same order in which they occur in some arc of G: if ai and ai+1 are adjacent nodes on the walk, then the ordered pair áai,ai+1ń must be an arc of G. An arc of a directed graph is like a one-way street, and a directed walk obeys all the one-way signs (arrowheads). An undirected walk through a directed graph is possible, simply by ignoring the ordering.
A graph is connected if there is a possible path (directed or undirected) between any two nodes. If it is not connected, then it breaks down into disjoint components, each of which is connected, but none of which has a path linking it to any other component. A cutpoint of a graph is a node, which when removed, causes the graph (or the component in which it is located) to separate into two or more disconnected components.
Certain special cases of graphs are important enough to be given special names: an acyclic graph is one that has no cycles, and a tree is an acyclic connected graph for which the path between any two nodes is unique. The most commonly used trees are rooted trees:
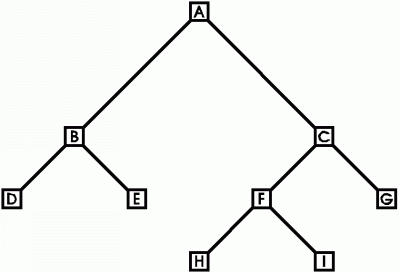
Figure 3: A binary tree
A binary tree is a rooted tree where every node that is not a leaf has exactly two children (Figure 3). In a binary tree, the two children of each node are usually designated as the left child and the right child. Since a tree has no cycles, a common convention for simplifying the diagrams is to omit the arrowheads on the arcs, but to draw the parent nodes at a higher level than their children. For Figure 3, the root A, which has no parent, is at the top; and the leaves, which have no children, are arranged along the bottom.
In computer applications, each node of a tree or other graph may have some associated data. To process that data, a program can take a walk through the tree and process the data at each node it visits. For the tree in Figure 3, imagine a walk that starts at the root, visits every node at least once, and stops when it returns to the root. Assume that the left child is always visited before the right child. Such a walk will visit the leaves of the tree only once, but it will visit each of the branching nodes three times: áA, B, D, B, E, B, A, C, F, H, F, I, F, C, G, C, Ań. There are therefore three options for processing the data at the branching nodes:
A common application of graph or tree walking algorithms is the translation of a parse tree or a conceptual graph to some natural or artificial language. The patterns of word order in various natual languages can be generated by different ways of walking through a conceptual graph and translating the concept nodes to words of the target language (Sowa 1984). Irish and Biblical Hebrew, for example, are preorder languages that put the verb first, Latin and Japanese are postorder languages that put the verb last, and English and Chinese are inorder languages that put the verb in the middle.
The terminology for graphs in this section is fairly standard, but many of the ideas have been developed independently by different people, who have introduced different terms. Some authors use the terms vertex and edge instead of node and arc. Others distinguish degrees of connectivity in a directed graph: it is strongly connected if there is a directed path between any two nodes, and it is weakly connected if there is only an undirected path between some pair of nodes. Some authors use the term digraph as an abbreviation for directed graph, but that use is confusing, since digraph should mean double graph. Occasionally, people introduce fancy terms like arborescence for rooted tree, but the simpler terminology is more descriptive.
<: R?R ® {true,false}.
When applied to the numbers 5 and 12, 5<12 has the value true,
but 12<5 has the value false. Dyadic relations are often written
as infix operators with special symbols, such as x<y or
xÎS. Sometimes, relations are
represented by single letters, such as R(x,y) or S(x,y,z).
For improved readability, they may be represented by arbitrarily long alphanumeric
strings, such as Mother(x,y) or Between(x,y,z). Traditional
mathematics uses single letters or symbols, but programming languages and
database systems usually have so many variables, functions, and relations
that longer names are preferred. The term predicate is often used
as a synonym for relation. Some authors, however, say that relations must
have two or more arguments and call a predicate with one argument a property.
As with other functions, relations may be defined either by intension or by extension. An intensional definition is a rule for computing a value true or false for each possible input. An extensional definition is a set of all n-tuples of arguments for which the relation is true; for all other arguments, the relation is false. One instance of a relation being true is represented by a single n-tuple, called a relationship; the relation itself is the totality of all relationships of the same type. A marriage, for example, is a relationship between two individuals, but the relation called marriage is the totality of all marriages.
The following table lists some common types of relations, an axiom that states the defining constraint for each type, and an example of the type. The symbol ® represents an arbitrary dyadic relation.
| Type | Axiom | Example |
|---|---|---|
| Reflexive | ("x) x®x | x is as old as y |
| Irreflexive | ("x) not(x®x) | x is the mother of y |
| Symmetric | ("x,y) x®y implies y®x | x is the spouse of y |
| Asymmetric | ("x,y) x®y implies not(y®x) | x is the husband of y |
| Antisymmetric | ("x,y) x®y and y®x implies x=y | x was present at y's birth |
| Transitive | ("x,y) x®y and y®z implies x®z | x is an ancestor of y |
The symbol ", called the universal quantifier, may be read for every or for all; it is discussed further in Section 9 on predicate logic. Some important types of relations satisfy two or more of the above axioms:
Let G be a graph, and let the symbol ® represent the corresponding dyadic relation. If x and y are nodes in the graph G, define x®y=true if the pair áx,yń is an arc of G, and x®y=false if áx,yń is not an arc of G. If the graph is undirected, then ® is symmetric because it satisfies the axiom x®y=y®x.
Although every dyadic relation can be represented by a graph, some extensions are necessary to represent multiple relations in the same graph. A common technique is to label the arcs of a graph with the names of the relations they represent. Informally, a labeled graph can be viewed as a set of graphs ľ one for each relation ľ overlaid on top of one another with the labels showing which relation each arc has been derived from. Formally, a labeled graph G can be constructed by the following steps:
Further extensions are needed to represent n-adic relations where ną2. Two kinds of generalized graphs may be used to represent n-adic relations: hypergraphs and bipartite graphs. The unlabeled versions can represent a single relation, and the labeled versions can represent an arbitrary collection of n-adic relations, including the possibility of allowing different relations to have a different valence or number of arguments.
Every arc of a bipartite graph has exactly two endpoints, but one
must be in C and the other must be in R. The set C
is the same as the set N of the hypergraph, but there is an isomorphism
between the set R of the bipartite graph and the set of arcs A
of the hypergraph: for each arc in A with n endpoints
áa1,...,anń
the corresponding node r of R is an endpoint of each of n
arcs
ár,a1ń,...,ár,anń.
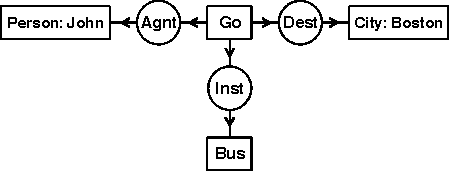
Figure 4: A conceptual graph represented as a labeled bipartite graph.
When bipartite graphs are used to represent conceptual graphs (CGs), the nodes in set C are called concepts and the nodes in set R are called conceptual relations. Figure 4 shows a conceptual graph that represents the English sentence John is going to Boston by bus. The boxes in Figure 4 represent concept nodes, and the circles represent conceptual relation nodes; every arc links a conceptual relation to a concept. Although a CG could be defined formally as either a hypergraph or a bipartite graph, the terminology of bipartite graphs maps more directly to the traditional way of drawing CGs. For a tutorial, see the examples of conceptual graphs. For the formal definitions, see the the draft proposed ANSI standard.
Since the Č and Ç operators on lattices are so similar to the unions and intersections of sets, they have many of the same properties. Following are the identities defined for the set operators that also hold for lattice operators:
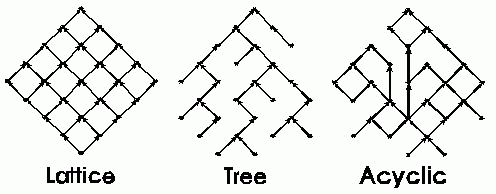
Graphs of mathematical lattices look like the lattices that one would expect a wisteria vine to climb on. Figure 5 shows the graphs for three kinds of partial orderings: a tree, a lattice, and a general acyclic graph. To simplify the drawings, a common convention for acyclic graphs is to omit the arrows on the arcs, but to assume that the arcs are directed either from the higher node to the lower node or from the lower node to the higher. For the partial ordering aŁb, the arc would be directed from a lower node a to a higher node b.
Figure 5: A lattice, a tree, and an acyclic graph
The term hierarchy is often used indiscriminately for any partial ordering. Some authors use the term hierarchy to mean a tree, and tangled hierarchy to mean an acyclic graph that is not a tree. In general, every tree is an acyclic graph, and every lattice is also an acyclic graph; but most lattices are not trees, and most trees are not lattices. In fact, the only graphs that are both trees and lattices are the simple chains (which are linearly ordered).
All the type hierarchies discussed in the book Knowledge Representation are partial orderings, and many of them are also lattices. Leibniz's Universal Characteristic, which is discussed in Section 1.1 of that book, defines a lattice of concept types in which the partial ordering operator Ł is called subtype.
Leibniz's method generates lattices with all possible combinations of attributes, but most combinations never occur in practice. The following table of beverages, which is taken from a paper by Michael Erdmann (1998), illustrates a typical situation in which many combinations do not occur. Some combinations are impossible, such as a beverage that is simultaneously alcoholic and nonalcoholic. Others are merely unlikely, such as hot and sparkling.
| Attributes | |||||
|---|---|---|---|---|---|
| Concept Types | nonalcoholic | hot | alcoholic | caffeinic | sparkling |
| HerbTea | x | x | |||
| Coffee | x | x | x | ||
| MineralWater | x | x | |||
| Wine | x | ||||
| Beer | x | x | |||
| Cola | x | x | x | ||
| Champagne | x | x | |||
Table of beverage types and attributes
To generate the minimal lattice for classifying the beverages in the above table, Erdmann applied the method of formal concept analysis (FCA), developed by Bernhard Ganter and Rudolf Wille (1999) and implemented in an automated tool called Toscana. Figure 6 shows the resulting lattice; attributes begin with lower-case letters, and concept types begin with upper-case letters.
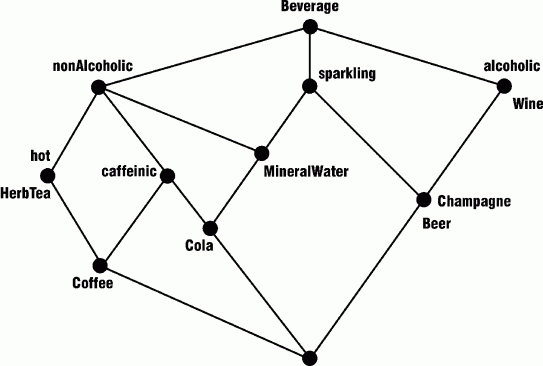
Figure 6: Lattice constructed by the method of formal concept analysis
In Figure 6, beer and champagne are both classified at the same node, since they have exactly the same attributes. To distinguish them more clearly, wine and champage could be assigned the attribute madeFromGrapes, and beer the attribute madeFromGrain. Then the Toscana system would automatically generate a new lattice with three added nodes:
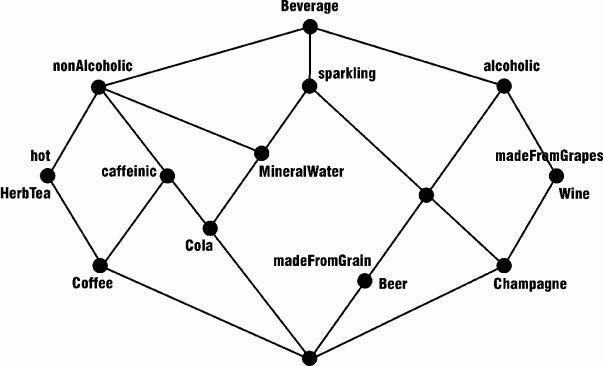
Figure 7: Revised lattice with new attributes
Note that the attribute nonalcoholic is redundant, since it is the complement of the attribute alcoholic. If that attribute had been omitted from the table, the FCA method would still have constructed the same lattice. The only difference is that the node corresponding to the attribute nonalcoholic would not have a label. In a lattice for a familiar domain, such as beverages, most of the nodes correspond to common words or phrases. In Figure 7, the only node that does not correspond to a common word or phrase in English is sparklingÇalcoholic.
Lattices are especially important for representing ontology and the techiques for revising, refining, and sharing ontologies. Each addition of a new attribute results in a new lattice, which is arefinement of the previous lattice. A refinement generated by FCA contains only the minimal number of nodes needed to accommodate the new attribute and its subtypes. Leibniz's method, which generates all possible combinations, would introduce superfluous nodes, such as hot Ç caffeinic Ç sparkling Ç madeFromGrapes. The FCA lattices, however, contain only the known concept types and likely generalizations, such as sparkling Ç alcoholic. For this example, Leibniz's method would generate a lattice of 64 nodes, but the FCA method generates only 14 nodes. A Leibniz-style of lattice is the ultimate refinement for a given set of attributes, and it may be useful when all possible combinations must be considered. But the more compact FCA lattices avoid the nonexistent combinations.
A further study of ontology raises questions about the origin of the various attributes and their relationships to one another. In Leibniz's method and the FCA method, the attributes madeFromGrapes and madeFromGrain are treated as independent primitives. Yet both of them could be analyzed as the dyadic madeFrom relation combined with either grapes or grain. Then madeFrom could be further analyzed into make and from, but the verb make would raise new questions about the difference between making wine from grapes and making a milkshake from milk. The plural noun grapes and the mass noun grain would also raise questions about quantification and measurement. A lattice is an important structure for organizing concept types, but a complete definition of those types leads to all the problems of language, logic, and ontology. For further discussion of those issues, see the paper "Concepts in the Lexicon".
Besides symbols for propositions, propositional logic also includes Boolean operators that represent logical relations such as and, or, not, and if-then. Let p be the proposition The sun is shining, and let q be the proposition It is raining. The most commonly used operators in propositional logic correspond to the English words and, or, not, if-then, and if-and-only-if:
The propositions represented in symbolic logic may be true or false. The rules of propositional logic compute the truth value of a compound proposition from the truth or falsity of the elementary propositions contained within it. They are therefore called truth functions, whose inputs are the truth values T for true and F for false. The following table, called a truth table, shows the outputs generated by the five truth functions Ů, Ú, ~, É, and ş for all possible combinations of the two inputs p and q.
| Inputs | Outputs | |||||
|---|---|---|---|---|---|---|
| p | q | pŮq | pÚq | ~p | pÉq | pşq |
| T | T | T | T | F | T | T |
| T | F | F | T | F | F | F |
| F | T | F | T | T | T | F |
| F | F | F | F | T | T | T |
There are 16 possible truth functions of two arguments, but the five listed in this table are the most commonly used. Another operator that is sometimes used is exclusive or, which is equivalent to p or q, but not both. Two operators commonly used in computer circuit design are nand and nor with the symbols &nand; and &nor;:
| p&nand;q | is equivalent to | ~(pŮq), |
| p&nor;q | is equivalent to | ~(pÚq). |
If one or two Boolean operators are taken as primitives, the others can be defined in terms of them. One common choice of primitives is the pair ~ and Ů. The other operators can be defined by the following combinations:
| pÚq | is equivalent to | ~(~p Ů ~q) |
| pÉq | is equivalent to | ~(p Ů ~q) |
| pşq | is equivalent to | ~(p Ů ~q) Ů ~(~p Ů q) |
In fact, only one primitive operator, either &nand; or &nor;, is necessary since both ~ and Ů can be defined in terms of either one of them:
| ~p | is equivalent to | (p &nand; p) |
| ~p | is equivalent to | (p &nor; p) |
| pŮq | is equivalent to | (p &nand; q) &nand; (p &nand; q) |
| pŮq | is equivalent to | (p &nor; p) &nor; (q &nor; q) |
Peirce's existential graphs, which are discussed in Chapter 5 of the book Knowledge Representation, use negation and conjunction as the two primitives. Peirce was also the first person to discover that all the other Boolean operators could be defined in terms of &nand; or &nor;.
"x(peach(x) É fuzzy(x)).The symbol " is called the universal quantifier, and the symbols peach and fuzzy are predicates or relations, such as the ones described in Section 5 on relations. The combination "x may be read for every x or for all x, the combination peach(x) may be read x is a peach, and the combination fuzzy(x) may be read x is fuzzy. The entire formula, therefore, may be read For every x, if x is a peach, then x is fuzzy. Since predicates (or relations) are functions that yield truth values as results and since the Boolean operators are functions that take truth values as their inputs, predicates can be combined with the same operators used in the propositional logic.
Besides the universal quantifier, predicate logic has an existential quantifier represented as $. The combination $x may be read there exists an x such that. The following formula uses an existential quantifier:
~$x(peach(x) Ů ~fuzzy(x)).This may be read It is false that there exists an x such that x is a peach and x is not fuzzy. Formulas with more than one quantifier are possible. The English statement For every integer x, there is a prime number greater than x is represented as
"x$y(integer(x) É (prime(y) Ů x<y)).Literally, this formula may be read For every x, there exists a y such that if x is an integer, then y is prime and x is less than y.
The two kinds of quantifiers, Boolean operators, variables, predicates, and the rules for putting them together in formulas make up the entire notation of first-order predicate calculus, which is also known as first-order logic or FOL. It is called first order because the range of quantifiers is restricted to simple, unanalyzable individuals.
Higher-order logic or HOL goes beyond FOL by allowing function variables and predicate variables to be governed by quantifiers. An example of a higher-order formula is the axiom of induction:
"P((P(0) Ů "n(P(n) É P(n+1)) É "nP(n)).This formula may be read For every predicate P, if P is true of 0, and for every n, P(n) implies P(n+1), then P is true of every n. This is the only axiom for arithmetic that requires more expressive power than first-order logic.
Any of the functions, operators, relations, and predicates of Sections 1 through 6 can also be used in the formulas of first-order logic. Following are the formation rules that define the syntax of formulas:
The formation rules of first-order logic are an example of a recursive definition. By applying them repeatedly, any possible formula can be derived. Suppose that f is a monadic function and + is a dyadic operator; then f(x) and 2+2 are terms. (By the conventions of Section 2, functions written with single characters are called operators, but they form terms just like other functions.) If P is a dyadic predicate and Q is a monadic predicate, then P(f(x),2+2) and Q(7) are atoms. Since all atoms are formulas, these two formulas can be combined by the Boolean operator É to form a new formula:
(P(f(x),2+2) É Q(7)).Since any formula may be preceded by ~ to form another formula, the following formula may be derived:
~(P(f(x),2+2) É Q(7)).Putting the quantifier "y in front of it produces
"y~(P(f(x),2+2) É Q(7)).Adding another quantifier $x produces
$x"y~(P(f(x),2+2) É Q(7)).And preceding this formula with ~ produces
~$x"y~(P(f(x),2+2) É Q(7)).In this formula, the occurrence of x in f(x) is bound by the quantifier $x, but the quantifier "y has no effect on the formula since there is no other occurrence of the variable y.
The order of quantifiers in predicate logic makes a crucial difference, as it does in English. Consider the sentence Every man in department C99 married a woman who came from Boston, which may be represented by the formula,
"x$y((man(x) Ů dept(x,C99)) É (woman(y) Ů hometown(y,Boston) Ů married(x,y))).This formula says that for every x there exists a y such that if x is a man and x works in department C99, then y is a woman, the home town of y is Boston, and x married y. Since the dyadic predicate married is symmetric, married(Ike,Mamie) is equivalent to married(Mamie,Ike). Interchanging the arguments of that predicate makes no difference, but interchanging the two quantifiers leads to the formula,
$y"x((man(x) Ů dept(x,C99)) É (woman(y) Ů hometown(y,Boston) Ů married(x,y))).This formula says that there exists a y such that for every x, if x is a man and x works in department C99, then y is a woman, the home town of y is Boston, and x married y. In ordinary English, that would be the same as saying, A woman who came from Boston married every man in department C99. If there is more than one man in department C99, this sentence has implications that are very different from the preceding one.
The first version of predicate logic was developed by Gottlob Frege (1879), but in a notation that no one else ever used. The more common algebraic notation, which has been presented in this section, was defined by Charles Sanders Peirce (1883, 1885), but with a different choice of symbols for the quantifiers and Boolean operators. Giuseppe Peano (1889) adopted the notation from Peirce and introduced the symbols that are still in use today. That notation is sometimes called Peano-Russell notation, since Alfred North Whitehead and Bertrand Russell popularized it in the Principia Mathematica. But it is more accurate to call it Peirce-Peano notation, since the extensions that Russell and Whitehead added are rarely used today. The notation presented in this section is Peirce's algebraic notation with Peano's choice of symbols. For a survey of other notations for logic, see the examples that compare predicate calculus to conceptual graphs and the Knowledge Interchange Format (KIF). Aristotle presented his original syllogisms in a stylized version of Greek, and modern computer systems sometimes represent predicate calculus in a stylized or controlled natural language.
"x(peach(x) É fuzzy(x)) ~$x(peach(x) Ů ~fuzzy(x))To prove that these formulas are equivalent, it is necessary to find two proofs. One proof would start with the first formula as hypothesis and apply the rules of inference to derive the second. The second proof would start with the second formula as hypothesis and derive the first.
Any equivalence, whether assumed as a definition or proved as a theorem, can be used to derive one formula from another by the rule of substitution. For any formula A, either of the following two equivalences may be assumed as a definition, and the other can be proved as a theorem:
| $xA | is equivalent to | ~"x~A |
| "xA | is equivalent to | ~$x~A |
Since these equivalences are true when A is any formula whatever, they remain true when any particular formula, such as (peach(x) É fuzzy(x)), is substituted for A. With this substitution in both sides of the equivalence for ", the left side becomes identical to the first peach formula above, and the right side becomes the following formula:
~$x~(peach(x) É fuzzy(x)).This formula can be tranformed to other equivalent formulas by using any of the equivalences given in Section 8. For any formulas p and q, the formula pÉq was defined as equivalent to the formula ~(pŮ~q). Therefore, the next formula can be derived by subsituting peach(x) for p and fuzzy(x) for q:
~$x~~(peach(x) Ů ~fuzzy(x)).For any formula p, the double negation ~~p is equivalent to p. Therefore, the double negation in the previous formula can be deleted to derive
~$x(peach(x) Ů ~fuzzy(x)),which is identical to the second peach formula. Therefore, the second peach formula can be proved from the first.
To prove that both peach formulas are equivalent, another proof must start with the second formula as hypothesis and derive the first formula. For this example, the second proof is easy to find because each step in the previous proof used an equivalence. Therefore, each step can be reversed to derive the first formula from the second. Most proofs, however, are not reversible because some of the most important rules of inference are not equivalences.
Following are some rules of inference for the propositional logic. The symbols p, q, and r represent any formulas whatever. Since these symbols can also represent formulas that include predicates and quantifiers, these same rules can be used for predicate logic. Of these rules, only the rule of conjunction is an equivalence; none of the others are reversible.
Following are some common equivalences. When two formulas are equivalent, either one can be substituted for any occurrence of the other, either alone or as part of some larger formula:
For predicate logic, the rules of inference include all the rules of propositional logic with additional rules about substituting values for quantified variables. Before those rules can be stated, however, a distinction must be drawn between free occurrences and bound occurrences of a variable:
Noam Chomsky (1956, 1957) used production rules for specifying the syntax of natural languages, and John Backus (1959) used them to specify programming languages. Although Chomsky and Backus both adopted their notations from Post, they found that the completely unrestricted versions used by Thue, Post, and Markov were more powerful than they needed. Backus limited his grammars to the context-free rules, while Chomsky also used the more general, but still restricted context-sensitive rules. The unrestricted rules can be inefficient or undecidable, but the more restricted rules allow simpler, more efficient algorithms for analyzing or parsing a sentence.
A grammar has two main categories of symbols: terminal symbols like the, dog, or jump, which appear in the sentences of the language itself; and nonterminal symbols like N, NP, and S, which represent the grammatical categories noun, noun phrase, and sentence. The production rules state how the nonterminal symbols are transformed in generating sentences of the language. Terminal symbols are called terminal because no production rules apply to them: when a derivation generates a string consisting only of terminal symbols, it must terminate. Nonterminal symbols, however, keep getting replaced during the derivation. A formal grammar G has four components:
A ® Bwhere A is a sequence of symbols having at least one nonterminal, and B is the result of replacing some nonterminal symbol in A with a sequence of symbols (possibly empty) from T and N. The start symbol corresponds to the highest level category that is recognized by the grammar, such as sentence. The production rules generate sentences by starting with the start symbol S and systematically replacing nonterminal symbols until a string consisting only of terminals is derived. A parsing program applies the rules in reverse to determine whether a given string is a sentence that can be generated from S. Grammars of this form are called phrase-structure grammars because they determine the structure of a sentence as a hierarchy of phrases.
Some convention is needed to distinguish terminals from nonterminals. Some people write terminal symbols in lower case letters and nonterminals in upper case; other people adopt the opposite convention. To be explicit, this section will enclose terminal symbols in double quotes, as in "the" or "dog". To illustrate the formalism, the following grammar defines a small subset of English:
S ® NP VP NP ® Det N VP ® V NP Det ® "the" Det ® "a" N ® "cat" N ® "dog" V ® "saw" V ® "chased"This grammar may be used to generate sentences by starting with the symbol S and successively replacing nonterminal symbols on the left-hand side of some rule with the string of symbols on the right:
S NP VP Det N VP a N VP a dog VP a dog V NP a dog chased NP a dog chased Det N a dog chased the N a dog chased the dogSince the last line contains only terminal symbols, the derivation stops. When more than one rule applies, any one may be used. The symbol V, for example, could have been replaced by saw instead of chased. The same grammar could be used to parse a sentence by applying the rules in reverse. The parsing would start with a sentence like a dog chased the dog and reduce it to the start symbol S.
The production rules for the above grammar belong to the category of context-free rules. Other classes of grammars are ranked according to the complexity of their production rules. The following four categories of complexity were originally defined by Chomsky:
A ® x B C ® ywhere A, B, and C are single nonterminal symbols, and x and y represent single terminal symbols. Note that finite-state grammars may have recursive rules of the form A ® x A, but the recursive symbol A may only occur as the rightmost symbol. Such recursions, which are also called tail recursions, can always be translated to looping statements by an optimizing compiler.
A ® B C ... Dwhere A is a single nonterminal symbol, and B C ... D is any sequence of one or more symbols, either terminal or nonterminal. In addition to the tail recursions permitted by a finite-state grammar, a context-free grammar allows recursive symbols to occur anywhere in the replacement string. A recursive symbol in the middle of the string, called an embedded recursion, cannot in general be eliminated by an optimizing compiler. Such recursions require a parsing program to use a pushdown stack or an equivalent technique to manage temporary storage.
a A z ® a B C ... D zwhere A is a single nonterminal symbol, a and z are strings of zero or more symbols (terminal or nonterminal), and B C ... D is a string of one or more terminal or nonterminal symbols. To analyze a context-sensitive grammar, a parsing program requires a symbol table or an equivalent storage-management technique to keep track of context dependencies.
Once a grammar is defined, all grammatical sentences in the language can be generated by the following procedure:
For convenience, production rules may be written in an extended notation, which uses some additional symbols. The new symbols do not increase the number of sentences that can be derived, but they reduce the total number of grammar rules that need to be written. The following extensions, which define regular expressions, are used in Unix utilities such as grep and awk.
Some examples may help to show how the extended notation reduces the number rules. By using the vertical bar, the following two production rules,
N ® "cat" N ® "dog"can be combined in a single rule:
N ® "cat" | "dog"If the grammar permits a noun phrase to contain an optional adjective, it might use the following two rules to define NP:
NP ® Det N NP ® Det Adj NThen both rules can be combined by using the question mark to indicate an optional adjective:
NP ® Det Adj? NIf an optional list of adjectives is permitted, then the question mark can be replaced with an asterisk:
NP ® Det Adj* NThis single rule in the extended notation is equivalent to the following four rules in the basic notation:
NP ® Det N NP ® Det AdjList N AdjList ® Adj AdjList ® Adj AdjListThe last production rule has a tail recursion, in which the leftmost symbol AdjList is replaced by a string that includes the same symbol. To generate an unlimited number of possible sentences, a grammar must have at least one rule that is directly or indirectly recursive. Since the sample grammar for a fragment of English had no recursive rules, it could only generate a finite number of different sentences (in this case 32). With the addition of a recursive rule such as this, it could generate infinitely many sentences (all of which would be rather boring).
By allowing embedded recursions, the more general context-free grammars can enforce constraints that cannot be expressed in a finite-state or regular grammar. The following two rules, for example, generate all strings consisting of n left parentheses followed by n right parentheses:
S ® "(" S ")"
S ® "(" ")"
Since each rule adds a balanced pair of parentheses, the result of applying
these rules any number of times must always be balanced. A finite-state
grammar or a regular expression cannot guarantee that the number of parentheses
on the right matches the number on the left. The following regular expression,
for example, generates too many strings:
S ® "("+ ")"+
Besides the strings of balanced parentheses, it generates strings like
"())))" and "((((())". A context-free grammar can ensure that the two sides
are balanced by generating part of the right side and the corresponding
part of the left side in the same rule. A context-sensitive grammar can
impose more general constraints that depend on combinations of symbols
that occur anywhere in the string. A general-rewrite grammar can impose
any constraint that can be formulated in any programming language.
This section describes a common type of games called two-person zero-sum perfect-information games. They are called two-person games to distinguish them from games like poker with many players; they are zero-sum games because anything that one player loses the other player wins (as distinguished from negative-sum games where the house takes a cut or positive-sum games where new values are created); and they are perfect-information games because each player can see the complete state at all times (as distinguished from poker or bridge where some of the most significant information is hidden). Following are some basic definitions:
The play of the game consists of moves from state to state. If more than one move is permitted in a given state, the player on move has the right to choose which one to play. For a state áp1,...,pnń, the first symbol p1 identifies the player on move, and the remaining information p2,...,pn depends on the type of game. In chess, for example, the current state describes the location of all the pieces on the board, but it also includes control information about the possibility of castling or en passant pawn captures.
Since the payoff function is only defined for ending states, the value at nonending states may be computed on the assumption that each player makes an optimal choice at each move. In choosing moves, A's strategy is to maximize the payoff, and B's strategy is to minimize the payoff. Therefore, the usual method for computing the value at a state P of a game G is called a minimax algorithm because it alternately tries to minimize or maximize the predicted value depending on which player is on move. The value at state P is determined by a recursive function value(P):
To say of what is that it is not, or of what is not that it is, is false,For Aristotle, these conditions define what it means for a sentence in a natural language to be true about the world. Tarski, however, made two important simplifications. First, he restricted his definitions to formalized languages, in particular, to first-order predicate logic. Second, he replaced the complexities of the real world by an abstract "model of an axiom system." For an informal discussion of Tarski's approach, see his paper "The Semantic Conception of Truth".
while to say of what is that it is, or of what is not that it is not, is true.
Formally, a model M consists of a set D of entities called a domain of individuals and a set R of relations defined over the individuals in D. To determine whether a sentence is true or false, model theory defines an evaluation function F, which can be applied to any formula p in first-order logic and any model M=áD,Rń:
One of the most complicated features of Tarski's original definition is his method of assigning entities in the domain D to the variables in the formula p. Although his definition is mathematically correct, it is inefficient to compute for finite domains and impossible to compute for infinite domains. As an example, consider the statement For every integer n, the integer 2n is even. In predicate calculus, that statement could be expressed by the following formula:
("n)($m)(integer(n) É (times(2,n,m) Ů even(m))).
According to Tarski's original definition, the truth of this formula is
determined by assigning all possible integers to the variable
n
and checking whether there exists a value of m that makes the body
of the formula true for each assignment. Such a computation is impossible
for infinite domains and extremely inefficient even for finite domains.
To simplify the evaluation of F, the logician Jaakko Hintikka (1973, 1985) developed game-theoretical semantics as a systematic method for assigning values to the variables one at a time. Risto Hilpinen (1982) showed that game-theoretical semantics is equivalent to the method of endoporeutic, which Peirce developed for determining the truth value of an existential graph. Sowa (1984) adopted game-theoretical semantics as the method for defining the semantics of conceptual graphs. In an introductory textbook for teaching model theory, Barwise and Etchemendy (1993) adopted game-theoretical semantics and wrote a computer program to teach their readers how to play the game. Game-theoretical semantics is mathematically equivalent to Tarski's original definition, but it is easier to explain, easier to generalize to a wide variety of languages, and more efficient to implement in computer programs.
In game-theoretical semantics, every formula p determines a two-person zero-sum perfect-information game, as defined in Section 12. The two players in the evaluation game are the proposer, who wins the game by showing that p is true, and the skeptic, who wins by showing that p is false. To play the game, the two players analyze p from the outside in, according to the following rules. The rules progressivley simplify the formula p by removing quantifiers and Boolean operators until the formula is reduced to a single atom.
To illustrate the evaluation game, compute the denotation of the formula that expresses the statement For every integer n, the integer 2n is even:
("n)($m)(integer(n) É (times(2,n,m) Ů even(m))).
For this example, the domain D is the set of all integers and the
set of relations R would include the relations named times,
integer, and even. Since the extensions of these relations
contain infinitely many tuples, they could not be stored explicitly on
a computer, but they could easily be computed as needed.
($m)(integer(17) É (times(2,17,m) Ů even(m))).
integer(17) É (times(2,17,34) Ů even(34)).
~integer(17) Ú (times(2,17,34) Ů even(34)).
times(2,17,34) Ů even(34).
times(2,17,34).
times(2,n,2n) Ů even(2n).Since both sides of the Ů operator must be true, the skeptic has no possibility of winning. Therefore, the proposer is guaranteed to win, and the formula is true.
This example shows that a winning strategy can often be found for models that allow infinitely many possible moves. Leon Henkin (1959) showed that game-theoretical semantics could also be applied to infinitely long formulas. In some cases, the truth value of an infinite formula can be computed in just a finite number of steps. For example, consider an infinite conjunction:
p1 Ů p2 Ů p3 Ů ...If this formula happens to be true, the evaluation game would take infinitely long, since every pi would have to be tested. But if it is false, the game would stop when the skeptic finds the first false pi. A similar optimization holds for infinite disjunctions:
p1 Ú p2 Ú p3 Ú ...If a disjunctive formula is false, the evaluation game would take infinitely long. But if it is true, the game would stop when the proposer finds the first true pi. Although nothing implemented in a computer can be truly infinite, a typical database or knowledge base may have millions of options. Tarski's original definition would require an exhaustive check of all possibilities, but the game-theoretical method can prune away large branches of the computation. In effect, the optimizations are equivalent to the optimizations used in computer game-playing programs. They are also similar to the methods used to answer an SQL query in terms of a relational database.
Anyone who has found these notes useful may also be interested in the following on-line resources:
The MathArchives topics on discrete mathematics.
An on-line tutorial on sets, logic, and proofs.
Copyright ©1999 by John F. Sowa. Permission is hereby granted for anyone to make verbatim copies of this document for teaching, self-study, or other noncommercial purposes provided that the copies cite the author, the URL of this document, and this permission statement. Please send comments to John Sowa.
Last Modified: